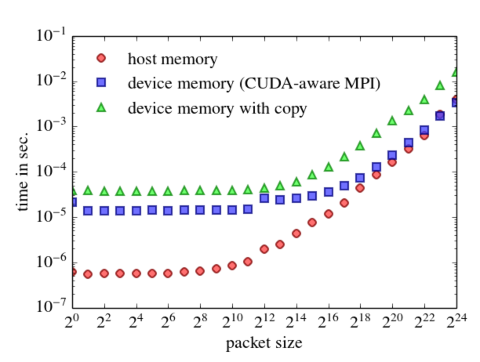
CUDA and MPI provide two different APIs for parallel programming that target very different parallel architectures. While CUDA allows to utilize parallel graphics hardware for general purpose computing, MPI is usually employed to write parallel programs that run on large SMP systems or on cluster computers. In order to improve a cluster’s overall computational capabilities it is not unusual to equip the nodes of a cluster with graphics cards. This, however, adds also another level of parallelism that a programmer must cope with. Likely one will combine MPI with CUDA when writing programs for such a system. Combining both kinds of parallel programming techniques becomes much easier if the MPI implementation is CUDA-aware. CUDA-aware means that one can send data from device memory of one graphics card directly to the device memory of another card without an intermediate copy to host memory. This magic becomes possible thanks to «unified virtual address space» that puts all CUDA execution, on CPU and on the GPU, into a single address space. (Unified virtual address space requires CUDA 4.0 or later and a GPU with compute capability 2.0 or higher.) CUDA-aware MPI eases multi-GPU programming a lot and improves performance. Among other implementations, Open MPI is CUDA-aware.
The following program below sends a message from one GPU to another via MPI. The program may be compiled with
mpic++ -o ping_pong ping_pong.cc -lcuda -lcudart
It should be run on a node with two or more GPUs and all of them set to compute mode «exclusive process». There is an obstacle when starting the program via mpirun. mpirun may not find the library libcuda.so or try to load the wrong library (e.g. a 32-bit library on a 64-bit system). In this case set the environment variable LD_LIBRARY_PATH to an appropriate value.
#include <cstdlib>
#include <cstring>
#include <iostream>
#include "mpi.h"
#include <cuda.h>
#include <cuda_runtime.h>
int main(int argc, char *argv[]) {
MPI_Init(&argc, &argv);
int myrank, nprocs;
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
const int str_max_len=32;
char str[str_max_len];
char *str_d;
cudaMalloc(&str_d, str_max_len);
if (nprocs>=2 and myrank==0) {
std::strncpy(str, "Hello world!", str_max_len);
cudaMemcpy(str_d, str, str_max_len, cudaMemcpyHostToDevice);
MPI_Send(str_d, str_max_len, MPI_CHAR, 1, 0, MPI_COMM_WORLD);
}
if (nprocs>=2 and myrank==1) {
MPI_Status stat;
MPI_Recv(str_d, str_max_len, MPI_CHAR, 0, 0, MPI_COMM_WORLD, &stat);
cudaMemcpy(str, str_d, str_max_len, cudaMemcpyDeviceToHost);
std::cout << "got \"" << str << "\"" << std::endl;
}
cudaFree(str_d);
MPI_Finalize();
return EXIT_SUCCESS;
}
The message throughput may be measured by a simple ping-pong test.
// ping_pong.cc
//
// determine bandwidth as a function of packet size
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <string>
#include "mpi.h"
#include <cuda.h>
#include <cuda_runtime.h>
const int max_packet_size=0x1000000; // maximal message size
const int count=250; // number of messages
char *buff, *buff_2; // buffers
typedef enum { host, device, copy } benchmark_type;
int main(int argc, char *argv[]) {
if (argc!=2){
std::cerr << "usage: " << argv[0] << " [--host|--device|--copy]\n";
std::exit(EXIT_FAILURE);
}
std::string arg_str(argv[1]);
if (arg_str!="--host" and
arg_str!="--device" and
arg_str!="--copy") {
std::cerr << "usage: " << argv[0] << " [--host|--device|--copy]\n";
std::exit(EXIT_FAILURE);
}
benchmark_type benchmark;
if (arg_str=="--host")
benchmark=host;
else if (arg_str=="--device")
benchmark=device;
else if (arg_str=="--copy")
benchmark=copy;
else { // shold never be reached
std::cerr << "usage: " << argv[0] << " [--host|--device|--copy]\n";
std::exit(EXIT_FAILURE);
}
MPI::Init(); // initialize MPI
int rank=MPI::COMM_WORLD.Get_rank(); // get my rank
int size=MPI::COMM_WORLD.Get_size(); // get number of processes
std::string fname;
if (benchmark==host) {
buff=new char[max_packet_size]; // allocate host memory
fname="ping_pong_host.dat";
} else if (benchmark==device) {
cudaMalloc(&buff, max_packet_size); // allocate GPU memory
fname="ping_pong_device.dat";
} else {
buff=new char[max_packet_size]; // allocate host memory
cudaMalloc(&buff_2, max_packet_size); // allocate GPU memory
fname="ping_pong_copy.dat";
}
if (size==2) { // need exactly two processes
int device[2];
if (benchmark!=host) {
cudaGetDevice(device);
if (rank==0)
MPI::COMM_WORLD.Recv(&device[1], 1, MPI::INT, 1, 0);
else
MPI::COMM_WORLD.Send(&device[0], 1, MPI::INT, 0, 0);
}
std::ofstream out;
if (rank==0) { // open output file
out.open(fname.c_str());
if (!out)
MPI::COMM_WORLD.Abort(EXIT_FAILURE);
out << "# bandwidth as a function of packet size\n";
if (benchmark!=host)
out << "# process 0 using GPU " << device[0] << "\n"
<< "# process 1 using GPU " << device[1] << "\n";
out << "# clock resolution " << MPI::Wtick() << "sec.\n"
<< "# packet size\tmean time\tmaximal time\n";
}
cudaEvent_t start, stop;
if (benchmark==copy) {
cudaEventCreate(&start);
cudaEventCreate(&stop);
}
// try messages of different sizes
int packet_size=1;
while (packet_size<=max_packet_size) {
double t_av=0.0;
double t_max=0.0;
// average over several messages
for (int i=0; i<count; ++i) {
MPI::COMM_WORLD.Barrier(); // synchronize processes
if (rank==0) {
double t=MPI::Wtime(); // start time
if (benchmark==copy) {
cudaEventRecord(start, 0);
cudaMemcpy(buff, buff_2, packet_size, cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
}
MPI::COMM_WORLD.Send(buff, packet_size, MPI::CHAR, 1, 0);
if (benchmark==copy) {
cudaEventRecord(start, 0);
cudaMemcpy(buff_2, buff, packet_size, cudaMemcpyHostToDevice);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventRecord(start, 0);
cudaMemcpy(buff, buff_2, packet_size, cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
}
MPI::COMM_WORLD.Recv(buff, packet_size, MPI::CHAR, 1, 0);
if (benchmark==copy) {
cudaEventRecord(start, 0);
cudaMemcpy(buff_2, buff, packet_size, cudaMemcpyHostToDevice);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
}
t=(MPI::Wtime()-t)/2.0; // time difference
t_av+=t;
if (t>t_max)
t_max=t;
} else {
if (benchmark==copy) {
cudaEventRecord(start, 0);
cudaMemcpy(buff, buff_2, packet_size, cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
}
MPI::COMM_WORLD.Recv(buff, packet_size, MPI::CHAR, 0, 0);
if (benchmark==copy) {
cudaEventRecord(start, 0);
cudaMemcpy(buff_2, buff, packet_size, cudaMemcpyHostToDevice);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventRecord(start, 0);
cudaMemcpy(buff, buff_2, packet_size, cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
}
MPI::COMM_WORLD.Send(buff, packet_size, MPI::CHAR, 0, 0);
if (benchmark==copy) {
cudaEventRecord(start, 0);
cudaMemcpy(buff_2, buff, packet_size, cudaMemcpyHostToDevice);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
}
}
}
if (rank==0) { // print results to file
t_av/=count;
out << packet_size << "\t\t" << t_av << "\t" << t_max << "\n";
}
packet_size*=2; // double packet size
}
if (rank==0) // close file
out.close();
}
MPI::Finalize(); // finish MPI
return EXIT_SUCCESS;
}